
How to Scrape Amazon Product Data with Python (2025)
Are you struggling to extract the right product data from Amazon's vast catalog? Keeping up with product prices, customer reviews, and inventory updates can feel impossible as the marketplace keeps changing.
Amazon's data is a goldmine of insights—if you can get past the barriers. Whether you are looking for product prices, customer reviews, or analyzing competitors, having reliable access to Amazon data is crucial.
That's where web scraping with Python comes in. It can help automate the process and make it easier to gather data from Amazon quickly and accurately.
But scraping Amazon isn't just about running a script. With advanced anti-scraping measures in place, understanding how to handle headers, delays, and parsing is critical.
In this guide, we'll walk you through the process of web scraping Amazon data with Python, showing you how to:
- Set up your tools and environment
- Overcome common scraping challenges
- Extract and analyze key product data like prices, reviews, and images
Let's get started!
Prerequisites for Scraping Amazon with Python
Before starting, make sure you have the right tools in place. Here's what you need to set up your Amazon web scraper:
1. Python installed
Download Python from python.org if it's not already installed on your system.
2. Project folder
Create a dedicated folder to keep your scripts and exported data organized for easier access.
3. Python libraries
Install the following libraries to handle HTTP requests, HTML parsing, and data management for your web scraping activity:
- requests: This is for sending HTTP requests and fetching raw HTML data
- BeautifulSoup: For parsing and extracting useful information from the HTML
- Pandas: For structuring and exporting the data
To install these libraries, run the following command in your terminal:
Step-by-Step Guide to Building an Amazon Scraper with Python
With your environment set up, let's walk through how to scrape Amazon product details.
1. Fetching HTML content from Amazon
To begin, you need to fetch the HTML content of an Amazon product page using the requests library. Here's a basic example of how to do that:
2. Handling rejections
Uh-oh! Sometimes Amazon tries to knock you off your board with rejections. If you run the code above, the response may not contain the page content you expect. Amazon scraping often blocks requests that appear automated. You might see:
- A CAPTCHA page
- An empty or unstructured response
This happens because the server detects that the request didn't originate from a browser.
3. Setting the User-Agent header
To avoid being blocked, you need to make your scraper's request appear as though it's coming from a real browser. One way to do this is by including a User-Agent header in your request.
Example of how to include it:
4. Fetching content with headers
Now, by adding the User-Agent header to your request, Amazon is less likely to block it. You'll receive the full HTML content of the product page:
5. Verifying the response
Once you run the code with the updated headers, Amazon will be less likely to block your request. You should now receive the correct HTML content for the product page.
Parsing Data from Amazon Product Pages
Now that you have access to the HTML, the next step is to extract the product details you're interested in, like the name, image, and price.
1. Key elements to target
Before parsing, identify which attributes you want to extract. The common elements to target on Amazon product pages are:
- Product Name
- Price
- Image URL
2. Finding the selectors for specific elements
To extract these attributes, you'll need to locate their unique CSS selectors. Use your browser's Inspect tool (F12) to examine the page's structure and identify the relevant selectors.
For example:
- Product Name is often in the
<span>tag with an ID likeproductTitle - Price is usually found in the
<span>tag with a class likea-price-whole - Image URL can be found in the
srcattribute of the<img>tag
Extracting Key Amazon Product Data Elements
When scraping data from Amazon product pages, it's important to focus on extracting key details that are most useful. Let's talk about how you can use BeautifulSoup to grab some details from a product page. For this example, we'll focus on the Apple 2024 MacBook Pro.
Extracting the product title
The product name is usually inside a <h1> tag with specific attributes like id or class. For example, the HTML might look like this:
To extract the title using BeautifulSoup, you can write:
Extracting the price
Product prices are usually stored in a <span> tag with classes like a-price or aok-offscreen. Here's an example of the HTML:
This code will help you extract the price:
Extracting high-resolution images
High-res images are often embedded in JavaScript code on the page, so you'll need regular expressions (regex) to locate them. For example, the URLs might look like this:
"hiRes":"https://example.com/image1.jpg"
You can extract these URLs from the page's HTML or JavaScript content with:
The pattern "hiRes":"(.+?)" is looking for the text "hiRes": followed by a URL. It captures everything that comes after "hiRes": up to the next quote mark (").
"hiRes":is the part it's looking for first(.+?)is a special way to grab everything between "hiRes": and the next quote mark. It matches any characters, like the URL, but stops when it hits the next quote
Writing the parsing script
Using the selectors, you can now extract data using BeautifulSoup. Below is the code for scraping the key elements:
If you have multiple product URLs to scrape, iterate through them in a loop:
Best Practices for Block Avoidance in Amazon Web Scraping
To avoid being blocked when scraping Amazon, use these strategies:
- Headers: Rotating user agents header with each request to mimic different browsers
- Delays: Introduce random delays between requests to simulate human browsing and prevent too many requests in a short time
- Randomized Intervals: Instead of fixed delays, use random intervals to make the scraping behavior look more natural
- Proxy Rotation: Change your IP address using proxies to avoid detection
To run these, install:
Here's how to implement it:
Exporting and Managing Scraped Data To CSV, Excel, And Google Sheets
Once you extract data from Amazon, the next step is to store it in a structured format so you can easily analyze and share it.
Two common ways to export and manage your scraped data are by saving it to CSV/Excel files or pushing it to Google Sheets for real-time updates.
1. Exporting to CSV and Excel
Once you've gathered the required data from Amazon using BeautifulSoup, you can store it in a structured format using Python's pandas library, which is great for organizing data into rows and columns, and then exporting it to CSV file or Excel.
Why Use CSV/Excel?
- CSV: Lightweight, easy to handle, and ideal for large datasets
- Excel: Offers more functionality, such as multiple sheets, formulas, and styling
Steps to Export Data Using pandas
- Organize the data: First, you'll collect all the scraped data and store it in a pandas DataFrame (a table-like structure with rows and columns)
- Export to CSV/Excel: After organizing the data, you can easily export it to your desired format
To get excel import functionality install:
Code Example:
df.to_csv(): Saves the data as a CSV filedf.to_excel(): Saves the data as an Excel file
2. Google Sheets integration for real-time updates
If you want to store your data in the cloud and share it with collaborators, or if you want real-time updates, Google Sheets is a great option. You can automate the process of pushing scraped data to Google Sheets using the gspread library.
Step 1: Set Up Google Sheets API
To get started with Google Sheets integration, you'll need to set up access to the Google Sheets API:
- Go to the Google Developers Console
- Create a new project
- Enable the Google Sheets API and Google Drive API
- Create a Service Account and download the JSON credentials file
- Share your Google Sheet with the service account's email (which is found in the credentials JSON)
Step 2: Install Required Libraries
You'll need the gspread and oauth2client libraries to interact with Google Sheets:
Step 3: Authenticate and Push Data
Once you've set up the API and installed the libraries, you can authenticate and push your scraped data to Google Sheets.
Code for Google Sheets Integration:
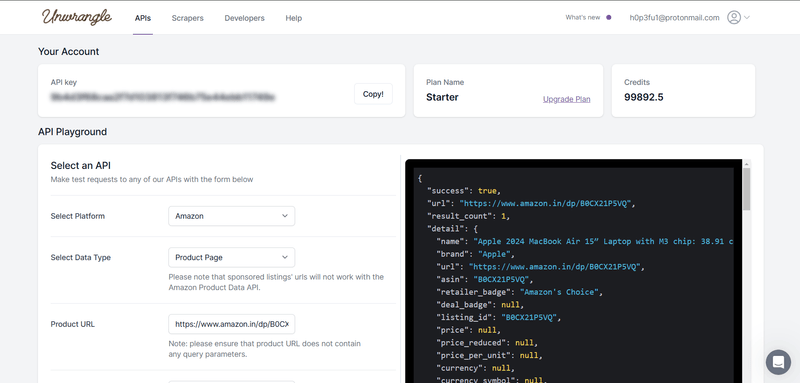
Need a Faster Solution? Try Unwrangle API
If you're looking for a quicker solution, consider using the Unwrangle's Amazon APIs for Amazon product data. Our Amazon scraper API offers:
- Product details, images, prices, and reviews
- Support for multiple countries
- Easy integration with JSON responses
By signing up and using an API key, you can start accessing Amazon product data right away, saving you the trouble of scraping yourself.
Frequently Asked Questions
Is it illegal to use a web scraper?
Web scraping itself is not inherently illegal, but its legality depends on how and what data you scrape. Always avoid private or copyrighted content and adhere to the website's terms of service.
Is it legal to scrape from Amazon?
Scraping publicly available product data like prices and titles on Amazon is generally acceptable, but you must respect Amazon's Terms of Service and ensure your activities do not overload their servers.
How do I scrape all Amazon products?
To scrape Amazon products, use an efficient scraper with proxies and rate limits. Focus only on publicly available data.
Does Amazon have anti-scraping measures?
Yes, Amazon uses robust anti-scraping technologies like CAPTCHA, IP bans, and monitoring of suspicious activity.