
How to Scrape Walmart.com: A Step-by-Step Tutorial (2025)
It's no secret that Walmart is a retail powerhouse, housing a vast collection of products across various categories. With so much product data readily available, it's no wonder that many businesses and analysts seek to tap into this wealth of information for market research and competitive analysis.
But how can we efficiently scrape this valuable data from Walmart's website?
In this guide, we'll walk you through the process of scraping Walmart's website using Python, to extract key product and review details.
Why Scrape Walmart with Python?
Python is renowned for its simplicity and versatility, making it an ideal choice for web scraping tasks. With an extensive set of libraries and frameworks, Python allows you to handle tasks like scraping easily. Its clean syntax makes it perfect for beginners, while its broad community support provides access to a plethora of resources that help overcome any challenges.
What We Will Scrape:
Our scraping efforts will focus on extracting the following product details:
- Product ID
- Type
- Name
- Brand
- Average Rating
- Short Description
- Thumbnail URL
- Price
- Currency Unit
Additionally, we will extract product reviews, including:
- Review Ratings
- Review Titles
- Review Text
- Submission Dates
- Verified Purchase Status
Preparing Your Python Environment
Before starting to scrape Walmart's product data, it's important to set up your Python environment with the necessary libraries.
What You Need to Install:
To begin, make sure Python is installed and that the following libraries are available:
- requests: To send HTTP requests and fetch HTML content from Walmart's web pages
- BeautifulSoup: For parsing and navigating through the HTML content to extract meaningful data
- json: For handling any json format data retrieved from Walmart's API, especially when scraping product details
How to Install These Libraries:
To install these libraries, run the following command in your terminal:
This will set up your environment and ensure you're ready to start scraping.
Understanding Walmart's Website Structure
Instead of scraping each product detail from the HTML, we'll take a more efficient route: extracting the data directly from the JavaScript embedded as JSON.
To see this data, you can open the browser's developer tools (just press F12), then look for a <script> tag with the id="__NEXT_DATA__". This is where all the product information is stored.
So why does Walmart use this method? Well, it's all thanks to the Next.js framework. This framework loads the data after the page is fully rendered. Essentially, when the page is built and the connection is established, all the data gets wrapped in a neat little JSON blob. But if the connection breaks or if we don't load the page fully, we might miss some of that crucial product information.
Now, here's the good news: this problem is easy to solve. We can scrape Walmart's product data in just two steps. Every website built with Next.js, like Walmart, has a <script> tag with id="__NEXT_DATA__". This tag contains all the JSON data we need!
The catch? This data is embedded through JavaScript. So, we can't simply make a regular HTTP GET request and grab it. Instead, we need to do a little more work: find the JSON data using BeautifulSoup (BS4) and then use Python's built-in JSON library to load it.
But before we walk through the process, there's a common issue you'll likely encounter: being blocked or redirected to an "Are You a Robot or Human?" page. This happens because Walmart uses anti-bot measures to detect and prevent automated scraping.
To avoid this frustration later on, it's important to simulate real user behavior. One of the simplest and most effective ways to achieve this is by adding a User-Agent header to your requests. The User-Agent mimics a real browser request, making it appear as if a legitimate user is accessing the website, rather than an automated scraper.
Here's an example of what the headers might look like:
Using these headers not only helps bypass basic bot detection but also increases the chances of successfully scraping data from Walmart without interruptions.
Extracting JSON Data from Walmart's Website
To extract the JSON data from Walmart's product pages, we'll follow a straightforward process using Python.
By leveraging the requests library to fetch the webpage and BeautifulSoup to parse the HTML, we can locate the <script> tag containing the JSON data.
Finally, we'll use Python's built-in JSON library to parse and save the data for further analysis.
Here's the code:
Now, the JSON data might look pretty huge and overwhelming at first. But here's a tip: use a JSON viewer to explore the structure and figure out where your desired data is located. You'll be able to drill down and find exactly what you're looking for.
Steps to View the JSON Data
-
Run the Code: Execute the script above, which will make a request to Walmart's product page and extract the JSON data embedded in the NEXT_DATA script.
-
Save the JSON Data: The extracted data will be saved in a file called full_data.json.
-
Open the JSON File: Once the data is saved, you can view it using a JSON Viewer. Popular options include:
-
The JSON Structure: JSON viewers allow you to explore and navigate the data. You'll be able to pinpoint specific product details like the name, price, description, and reviews. The viewer will let you expand and collapse different sections of the JSON structure to easily locate the information you need.
Step-by-Step Process for Scraping Product Data
To begin scraping product data, we'll be using the JSON data embedded within the NEXT_DATA script tag, as mentioned earlier. Here's a breakdown of the steps to extract the relevant product information:
1. Set Up the URL and Headers
Define the URL of the Walmart product page and set up the necessary headers to simulate a real browser. This helps prevent being blocked by Walmart's anti-scraping measures.
2. Make the Request and Parse HTML
Use requests.get() to send a request to the product page. Then, parse the HTML content using BeautifulSoup to locate the <script> tag that contains the JSON data.
3. Extract the JSON Data
Look for the <script> tag with the id="__NEXT_DATA__". This is where Walmart stores all the product data in JSON format.
4. Parse and Extract Relevant Product Details
Once we've found the <script> tag containing the JSON, we can parse it using Python's json library. From there, we extract the product details such as ID, name, type, brand, price, and more.
This will extract essential product information like the name, price, brand, description, and more.
Scraping Product Reviews from Walmart
Once we've scraped the product data, we can move on to scraping product reviews. Walmart stores its customer reviews in a similar fashion as product data.
1. Set Up Libraries and Parameters
We'll need the same libraries as before, along with the fake_useragent library to randomize the User-Agent header. You can also specify which product pages you want to scrape reviews for and how many review pages to fetch.
2. Iterate Over Product Codes and Review Pages
For each product code, we construct the URL to the review page and iterate through the review pages.
3. Extract Review Data
In this part of the script, we search for the NEXT_DATA tag within the review pages. Once found, we parse the JSON to extract customer reviews, including:
- Rating
- Review title
- Review text
- Submission date
- Verified purchase status
4. Save the Review Data
After extracting the reviews, save them to a JSON file for each product. You'll get a file named reviews_{product_code}.json, where {product_code} is the unique identifier for the product.
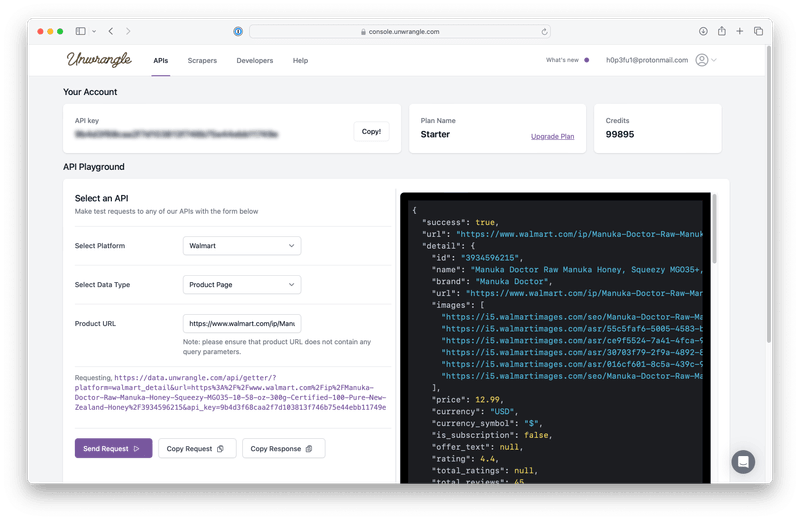
Looking for a Faster Solution? Try Unwrangle API
If you're looking for a quicker way to access Walmart product data, consider using the Unwrangle's Walmart Product API. This Walmart scraper API:
- Detailed product information: Get data like prices, images, reviews, and descriptions
- Comprehensive review scraping: Access customer reviews, ratings, and metadata in real time
- Seamless integration: Easy-to-use JSON responses for hassle-free data handling
By signing up and using an API key, you can start accessing Walmart products and review data instantly, saving time and effort.
Frequently Asked Questions
Is web scraping Walmart reviews legal?
Scraping publicly accessible data like product reviews is generally acceptable, but ensure compliance with Walmart's terms of service. Avoid accessing private or sensitive data and respect copyright laws.
How can I prevent being blocked while scraping Walmart?
To prevent being blocked, avoid sending too many requests too quickly. Implement rotating IPs or use proxy services, set user-agent headers to mimic real browsers, and respect Walmart's robots.txt file and rate limits.
Does Walmart have anti-scraping measures?
Yes, Walmart employs anti-bot measures such as CAPTCHAs, IP bans, and other mechanisms to detect and prevent automated scraping. To avoid getting blocked, consider using rotating proxies, adding headers like the User-Agent, and respecting rate limits.
Can I scrape Walmart product reviews?
Yes, Walmart product reviews can be scraped by accessing the product page's HTML or JSON data. You can use APIs, Python libraries, or tools like Unwrangle to extract customer reviews from Walmart product listings.