
How to Scrape E-Commerce Websites: A Complete Guide
Digitalization has skyrocketed the e-commerce sector in recent years. With increased digitalization, the demand for online shopping has risen, but with the demand, competition has also increased.
In this competition, businesses are always looking for ways to stay ahead. One of the most effective ways businesses can do this is by collecting valuable data from online retail platforms for competitive analysis. The best way to do this is through web scraping.
By scraping e-commerce websites, businesses can track competitor prices, monitor product trends, and gather insights into customer preferences. This helps them make smarter decisions and improve their overall strategy.
If you're looking to gain a competitive edge, we'll walk you through the necessary knowledge you need to scrape e-commerce websites.
Top Tools and Services for Scraping E-Commerce Websites
There are various tools available for scraping data from e-commerce websites, ranging from coding-based frameworks to no-code solutions. Below are some popular frameworks, libraries, and APIs commonly used for scraping.
BeautifulSoup (Python Library)
BeautifulSoup is a Python library for parsing HTML and XML documents. It provides a simple way to navigate through and extract data from static web pages. BeautifulSoup is known for its ease of use and flexibility in handling structured HTML content.
Scrapy (Python Framework)
Scrapy is an open-source Python framework designed for large-scale web scraping and crawling. It's ideal for scraping structured data from websites, especially those with consistent layouts. Its asynchronous architecture allows for efficient scraping of multiple pages at once, and it supports exporting data in various formats like JSON, CSV, and XML.
Selenium (Python/JavaScript/Java)
Selenium is a tool for automating web browsers, commonly used for scraping dynamic content rendered by JavaScript. It simulates real user interactions with websites, such as clicking buttons and scrolling through pages. Selenium supports multiple programming languages including Python, Java, and JavaScript, and works with various web browsers like Chrome and Firefox.
Puppeteer (Node.js)
Puppeteer is a Node.js library that provides control over a headless browser, allowing for the scraping of dynamic content and interactive web elements. Puppeteer excels at scraping websites that rely heavily on JavaScript rendering, and it can handle tasks like form submissions, clicking buttons, and taking screenshots.
Unwrangle
Unwrangle provides ready-to-use APIs that automate the process of scraping and structuring data. The API handles complex data extraction from popular e-commerce sites, offering organized data on products, prices, reviews, and more. It's designed to eliminate the need for custom scraping code.
How to Analyze E-Commerce Website Structures for Scraping
One of the most important skills you'll need is the ability to identify and understand the structure of the page.
When scraping e-commerce websites, it's crucial to understand the HTML structure to locate and extract the data you need. Below are the key concepts for effective web scraping.
1. Inspecting HTML Elements
Using browser developer tools (like Chrome's "Inspect" option) allows you to examine the HTML structure of a webpage. This helps you identify the tags, classes, and attributes needed to extract data, such as product prices or reviews.
2. CSS Selectors
CSS selectors help you target specific HTML elements, such as product names or prices. For example, .product-name or <h1> tags can be used to extract the data points needed for scraping.
3. Dynamic Page Structures and JavaScript
Modern websites often load content dynamically using JavaScript. In these cases, tools like Selenium or Puppeteer can simulate browser behavior and execute JavaScript to retrieve the data.
4. HTML Elements and Attributes
HTML tags like <div>, <span>, and <a>, along with classes, IDs, and attributes (e.g., href or src), help pinpoint the specific data you want to scrape, like links, images, and product details.
5. HTTP Requests
Understanding HTTP requests is crucial for scraping. You can monitor the network activity in developer tools to observe how data is fetched and replicate these requests using tools like Python's requests library or JavaScript's Axios.
6. Pagination
E-commerce websites often display data across multiple pages. By understanding pagination, whether through URL parameters or "Next" buttons, you can automate the process of scraping multiple pages to gather all the required data.
7. URL Pattern Analysis
By analyzing URL structures, such as example.com/product?page=2, you can develop strategies to navigate between pages and scrape data from individual product pages.
8. Web Scraper APIs
Some websites provide APIs to extract structured data directly. APIs can be more reliable and efficient than raw HTML scraping, as they offer organized data and are often easier to work with, but you must understand the API endpoints and parameters.
9. XPath Expressions
XPath is a language used to navigate HTML elements and extract specific data. XPath expressions are very powerful, often used in tools like Scrapy or Selenium to precisely target webpage elements, such as product names or prices.
Challenges in Scraping E-commerce Websites
Scraping e-commerce websites can be a rewarding but complex task due to the various challenges that arise from modern web technologies and security measures. These challenges can hinder the efficiency and accuracy of data extraction. Below are the key obstacles encountered when scraping e-commerce sites and how to overcome them.
1. Handling Dynamic Content
E-commerce websites often rely on JavaScript and AJAX to load content dynamically, meaning that data (such as product listings and prices) may not be available in the initial HTML of the page. This presents a challenge for traditional scrapers that rely on static HTML content.
2. Anti-Scraping Measures
To protect their data, e-commerce sites frequently implement anti-scraping mechanisms like IP blocking, rate limiting, and bot detection systems. These measures aim to prevent automated scraping and can block your requests if they detect suspicious behavior.
3. Dealing with CAPTCHAs
CAPTCHAs are another barrier commonly found on e-commerce websites. These tests are designed to distinguish between human users and bots, and encountering one can stop a scraper in its tracks.
4. Maintaining Data Accuracy and Consistency
Scraping e-commerce sites can result in data inaccuracies due to inconsistent product listings, website structure changes, or errors in scraping scripts. These issues can lead to incomplete or unreliable datasets.
5. Legal and Ethical Considerations
Web scraping is not without its legal and ethical concerns. It's important to respect the robots.txt file of a website and comply with its terms of service to avoid legal repercussions. Unauthorized scraping or violating copyright laws can result in penalties.
Best Practices and Techniques for Scraping E-Commerce Websites
Scraping e-commerce websites isn't as simple as running a script. With websites using advanced measures to block bots, you need to know how to handle headers, set delays, and work with dynamic content to get the data you need.
User-Agent
Websites identify requests through user agents to detect bots. To avoid being blocked, set a user agent that mimics a real browser (e.g., Chrome or Firefox). Use libraries like Faker (Python) to randomly generate user-agent strings for each request, reducing detection chances.
Rotating Proxies
Websites block scraping based on IP addresses. Using rotating proxies helps by distributing requests across multiple IPs, simulating human behavior. This makes it harder for websites to track and block your activities.
Handling Dynamic Content with Selenium or Puppeteer
Modern sites load content with JavaScript and AJAX, which can be missing in the initial HTML. Tools like Selenium (Python) and Puppeteer (Node.js) simulate user interactions (e.g., scrolling or clicking) and execute JavaScript, capturing dynamic data.
Scraping Data from APIs
Instead of scraping HTML, many sites provide structured data through APIs in formats like JSON or XML. Using an API is faster and more efficient than scraping raw HTML, as it provides data in a ready-to-use format.
Extracting Data with XPath
XPath allows you to precisely target elements in HTML, making it easy to extract specific data like product names or prices. It's particularly useful for navigating complex or dynamic content. Tools like Scrapy and Selenium support XPath for accurate data extraction.
Handling CAPTCHAs
CAPTCHAs are used to block bots. To bypass them, integrate CAPTCHA-solving services like 2Captcha or AntiCaptcha, which use human labor or algorithms to solve CAPTCHAs in real-time, allowing you to continue scraping without interruption.
Using Unwrangle to Scrape an E-Commerce Website
Unwrangle provides a hassle-free way to scrape data from e-commerce websites with its ready-to-use APIs. Instead of writing and maintaining custom scraping scripts, you can leverage Unwrangle's structured API solutions to extract data efficiently. It's especially useful for gathering detailed information from platforms like Amazon, saving time while delivering reliable results.
For instance, Unwrangle's Amazon Product Data API enables you to fetch comprehensive product details with a single API call. Whether you're tracking competitor prices, analyzing product reviews, or monitoring trends, this API makes the process seamless.
Features of Unwrangle's Amazon API
- Ease of Use: Fetch product data using a product URL or ASIN (Amazon Standard Identification Number)
- Detailed Data: Retrieve information such as product name, price, ratings, reviews, seller details, and more
- Structured Format: Get results in a clean JSON format, ready to use in analytics or applications
- Support for Variants: Track product variants, such as size or color, along with their availability and prices
- Supported Countries: Support for multiple countries such as the USA, India, and Brazil
Step-by-Step Tutorial: Scraping Amazon Data with Unwrangle using Python
Here's how to get started with web scraping e-commerce websites using Python:
Sign Up and Get Your API Key
- Visit the Unwrangle website and create an account.
- Obtain your API key, which will be required for authentication
Install Required Libraries
Ensure you have Python installed along with the requests library. If you don't have requests, install it using:
Write the Python Script
Use the following example script to scrape product data:
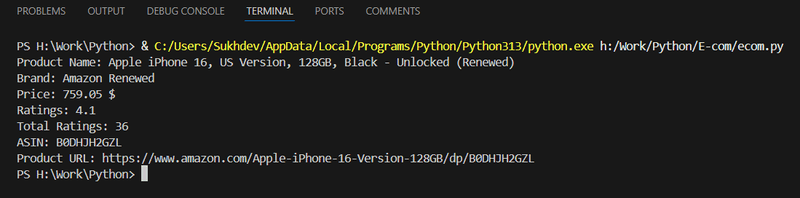
Run the Script
Save the script as scrape_amazon.py and run it using:
If everything is set up correctly, you'll see the product details printed in the terminal.
Customize the Output
Unwrangle's API provides rich data in JSON format. You can adjust the script to extract additional fields, such as:
- Product variants (size, color, etc.)
- Seller information
- Availability and delivery options
- Customer reviews and ratings
Modify the print statements or store the data in a structured format like CSV or a database for further use.
Need a Complete Solution? Try Unwrangle
Looking for an effortless way to scrape e-commerce data? Unwrangle's E-commerce APIs are your complete solution:
- Fetch real-time product details, search results, and customer reviews
- Skip the hassle of configuring parsers, rotating proxies, or solving CAPTCHAs
- Get structured JSON responses with a simple HTTP request
Sign up today and start scraping data from major retailers.